알고리즘 스터디 코드와 규칙 정리:
https://github.com/5jisoo/Algorithm-Study
GitHub - 5jisoo/Algorithm-Study: [2023 Winter ~ ] Algorithm Study ✏️ 알고리즘 스터디를 위한 저장소입니다.
[2023 Winter ~ ] Algorithm Study ✏️ 알고리즘 스터디를 위한 저장소입니다. - GitHub - 5jisoo/Algorithm-Study: [2023 Winter ~ ] Algorithm Study ✏️ 알고리즘 스터디를 위한 저장소입니다.
github.com
교재: 이것이 취업을 위한 코딩 테스트다 with 파이썬
DFS/BFS
그래프 탐색을 위한 대표적인 알고리즘.
- 탐색: 많은 양의 데이터 중에서 원하는 데이터를 찾는 과정.
- 자료구조: 데이터를 표현하고 관리하고 처리하기 위한 구조
재귀 함수
자기 자신을 다시 호출하는 함수
무한 호출을 방지하기 위해 재귀 함수의 종료 조건(if문)을 명시해야 함.
def recursive_function(i):
if i == 5: # 종료 조건
return
print(i, '번째 재귀 함수에서', i + 1, '번째 재귀 함수를 호출합니다.')
recursive_function(i + 1)
print(i, '번째 재귀 함수를 종료합니다.')
recursive_function(1)1 번째 재귀 함수에서 2 번째 재귀 함수를 호출합니다.
2 번째 재귀 함수에서 3 번째 재귀 함수를 호출합니다.
3 번째 재귀 함수에서 4 번째 재귀 함수를 호출합니다.
4 번째 재귀 함수에서 5 번째 재귀 함수를 호출합니다.
4 번째 재귀 함수를 종료합니다.
3 번째 재귀 함수를 종료합니다.
2 번째 재귀 함수를 종료합니다.
1 번째 재귀 함수를 종료합니다.
- 반복문의 사용보다 코드가 간결해짐.
- 재귀 함수가 수학의 점화식(재귀식)을 그대로 소스코드로 옮겼기 때문.
그래프 표현 방법
- 인접 행렬(Adjacency Matrix): 2차원 배열로 그래프의 연결 관계를 표현하는 방식
- 인접 리스트(Adjacency List): 리스트로 그래프의 연결 관계를 표현하는 방식
인접 행렬
2차원 배열에 각 노드가 연결된 형태를 기록하는 방식.
파이썬에서는 2차원 리스트로 구현함.
=> 연결이 되어 있지 않은 노드끼리는 무한의 비용이 발생한다고 작성.

INF = 999999999 # 무한의 비용 선언
# 2차원 리스트를 이용해 인접 행렬 표현
graph = [
[0, 7, 5],
[7, 0, INF],
[5, INF, 0]
]
print(graph)[[0, 7, 5], [7, 0, 999999999], [5, 999999999, 0]]
인접 리스트
모든 노드에 연결된 노드에 대한 정보를 차례대로 연결하여 저장함.


# 행이 3개인 2차원 리스트로 인접 리스트 표현
graph = [[] for _ in range(3)]
# 노드 0에 연결된 노드 정보 저장(노드, 거리)
graph[0].append((1, 7))
graph[0].append((2, 5))
# 노드 1에 연결된 노드 정보 저장(노드, 거리)
graph[1].append((0, 7))
# 노드 2에 연결된 노드 정보 저장(노드, 거리)
graph[2].append((0, 5))
print(graph)[[(1, 7), (2, 5)], [(0, 7)], [(0, 5)]]
두 방식의 차이
- 메모리
- 인접 행렬 방식은 모든 관계를 저장하므로 메모리 낭비가 심함.
- 인접 리스트 방식은 연결된 정보만을 저장하므로 메모리를 효율적으로 사용 가능.
- 시간
- 인접 리스트 방식은 특정한 두 노드가 연결되어 있는지에 대한 정보를 얻는 속도가 느림.
DFS
Depth-First Search. 깊이 우선 탐색
그래프의 깊은 부분을 우선적으로 탐색하는 알고리즘.

- 그래프는 노드(정점)와 간선으로 표현됨.
DFS 동작 과정
- 탐색 시작 노드를 스택에 삽입하고 방문 처리를 한다.
- 스택의 최상단 노드에 방문하지 않은 인접 노드가 있으면 그 인접 노드를 스택에 넣고 방문 처리를 한다. 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼낸다.
- 2번의 처리 과정을 더 이상 수행할 수 없을 때까지 반복한다.
DFS 동작 예시
일반적으로 인접한 노드 중 방문하지 않은 노드들 중에 번호가 낮은 순서대로 처리한다고 가정함.
(보통 코테에서 이렇게 명시하는 경우가 많음.)

==> 방문 처리된 노드는 파란색, 현재 처리하는 스택의 최상단 노드는 노란색으로 표현함.
- 시작 노드인 '1'을 스택에 삽입하고 방문 처리를 한다.

- 스택의 최상단 노드인 '1'에 인접하고 방문하지 않은 노드 '2', '3', '8' 중 가장 작은 '2'를 스택에 넣고 방문 처리 함.

- 스택의 최상단 노드 '2'에 방문하지 않은 인접 노드 '7'을 스택에 넣고 방문 처리 함.

- 스택의 최상단 노드 '7'에 방문하지 않은 인접노드 '6', '8' 중 작은 '6'을 스택에 넣고 방문 처리함.

- 스택의 최상단 노드 '6'에 방문하지 않은 인접노드 없음. 스택에서 '6'번 노드를 꺼냄.

- 스택의 최상단 노드 '7'에 방문하지 않은 인접 노드 '8' 존재. '8'번 노드를 스택에 넣고 방문 처리함.

- 스택의 최상단 노드 '8'에 방문하지 않은 인접노드 없음. 스택에서 '8'번 노드를 꺼냄.

- 스택의 최상단 노드 '7'에 방문하지 않은 인접노드 없음. 스택에서 '7'번 노드를 꺼냄
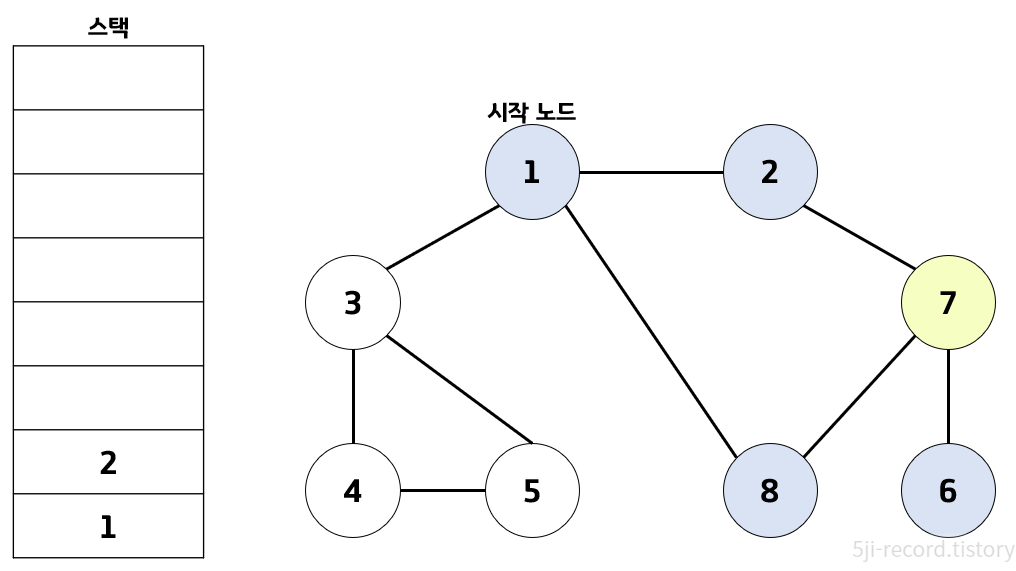
- 스택의 최상단 노드 '2'에 방문하지 않은 인접노드 없음. 스택에서 '2'번 노드를 꺼냄

- 스택의 최상단 노드 '1'에 방문하지 않은 인접노드 '3' 존재. '3'을 스택에 넣고 방문 처리함.

- 스택의 최상단 노드 '3'에 방문하지 않은 인접노드 '4', '5' 존재. 그중 작은 '4'를 스택에 넣고 방문 처리함.

- 스택의 최상단 노드 '4'에 방문하지 않은 인접노드 '5' 존재. '5'를 스택에 넣고 방문 처리함.

- 모든 노드가 방문처리 되었고, 결과적으로 노드의 탐색 순서(스택에 들어간 순서)는 다음과 같음
- 1 -> 2 -> 7 -> 6 -> 8 -> 3 -> 4 -> 5

DFS 코드 구현
def dfs(graph, v, visited):
visited[v] = True # 방문 처리
print(v, end=" ")
for i in graph[v]:
if not visited[i]:
dfs(graph, i, visited)
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
# 방문 정보
visited = [False] * 9
# dfs 함수 호출 - 시작 노드가 1이므로 처음에 1을 인수로 전달.
dfs(graph, 1, visited)1 2 7 6 8 3 4 5
BFS
Breadth First Search 알고리즘
'너비 우선 탐색':: 가까운 노드부터 탐색하는 알고리즘.
BFS 동작 과정
큐 자료구조를 이용함.
- 탐색 시작 노드를 큐에 삽입하고 방문 처리를 한다.
- 큐에서 노드를 꺼내 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리를 한다.
- 2번의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
BFS 동작 예시

==> 방문 처리된 노드는 파란색으로 큐에서 꺼내여 현재 처리하는 노드는 노란색으로 표시함.
- 시작 노드 '1'을 큐에 넣고 방문 처리를 함.

- 큐에서 노드 '1'을 꺼내고 방문하지 않은 인접 노드 '2', '3', '8'을 모듀 큐에 삽입하고 방문 처리 함.

- 큐에서 노드 '2'를 꺼내고 방문하지 않은 인접 노드 '7'을 큐에 삽입하고 방문 처리 함.

- 큐에서 노드 '3'을 꺼내고 방문하지 않은 인접 노드 '4', '5'를 큐에 삽입하고 방문 처리 함.

- 큐에서 노드 '8'을 꺼내고 방문하지 않은 인접 노드가 없으므로 무시함.

- 큐에서 노드 '7'을 꺼내고 방문하지 않은 인접 노드 '6'를 큐에 삽입하고 방문 처리 함.

- 남아 있는 노드에 방문하지 않은 인접 노드가 없다. 따라서 모든 노드를 차례대로 꺼내면 최종적으로 다음과 같음.

- 노드의 탐색 순서 (큐에 들어간 순서)
- 1 -> 2 -> 3 -> 8 -> 7 -> 4 -> 5 -> 6
BFS 코드 구현
deque 라이브러리를 사용하는 것이 좋으며 탐색 수행 시간이 O(N)임.
일반적인 경우 실제 수행 시간이 DFS보다 좋음.
from collections import deque
# BFS 메서드 정의
def bfs(graph, start, visited):
queue = deque([start]) # 큐 구현
visited[start] = True # 방문 처리
while queue: # 큐가 빌 때까지 반복
v = queue.popleft() # 원소 하나를 뽑아 출력
print(v, end=" ")
for i in graph[v]:
if not visited[i]:
queue.append(i)
visited[i] = True
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
# 방문 정보
visited = [False] * 9
# bfs 함수 호출
bfs(graph, 1, visited)1 2 3 8 7 4 5 6
간단 정리
| DFS | BFS | |
| 동작 원리 | 스택 | 큐 |
| 구현 방법 | 재귀 함수 이용 | 큐 자료구조(deque 라이브러리) 이용 |
- 이런식으로 2차원 배열로 나온 탐색 문제 역시도 각 데이터를 그래프의 형태로 바꾸어 풀이를 생각해낼 수도 있다.

코딩 테스트에서 탐색 문제를 보면 그래프 형태로 표현한 다음 풀이법을 고민하도록 하자!
교재 예제 정리하기
미로 탈출
생각해내지 못한 점
- 미로에서의 최소 거리를 어떻게 표시할까에 대한 아이디어
- 그 노드를 처음 방문할때, 그 전 노드 + 1 의 값을 노드에 저장하면 됨.
깨달은 점
- 문제에서 DFS, BFS 중 무엇을 사용해야하는지에 대한 감이 조금 잡힌 것 같다.
제출한 코드
from collections import deque
n, m = map(int, input().split())
visited = [[False] * m for _ in range(n)]
maze = []
for _ in range(n):
maze.append(list(map(int, input())))
count = 0
queue = deque([[0, 0]])
visited[0][0] = True
direction = [[0, 1], [0, -1], [1, 0], [-1, 0]]
while queue:
i, j = queue.popleft()
for di, dj in direction:
if 0 <= i + di <= n - 1 and 0 <= j + dj <= m - 1 \
and maze[i + di][j + dj] and not visited[i + di][j + dj]:
queue.append([i + di, j + dj])
maze[i + di][j + dj] = maze[i][j] + 1
visited[i + di][j + dj] = True
# maze 출력 확인
for i in range(n):
for j in range(m):
print(maze[i][j], end=" ")
print()
print()
print(maze[n - 1][m - 1])
'⌨️ Algorithm > Python' 카테고리의 다른 글
| [Python 문법] sum(), count(), map(), zip() 함수 정리 (0) | 2023.02.05 |
|---|---|
| [Algorithm] Week 5. 정렬 (0) | 2023.01.31 |
| [Python] itertools 라이브러리 (0) | 2023.01.19 |
| [Algorithm] Week 3. 구현 (0) | 2023.01.17 |
| [Python 문제풀이] 백준 11000번: 강의실 배정 (0) | 2023.01.14 |

댓글